Redes Neurais Artificiais
Redes neurais artificiais são modelos computacionais inspirados no cérebro humano, compostos por camadas de neurônios interconectados. Elas processam dados por meio de pesos, somas e funções de ativação para aprender padrões e fazer previsões.
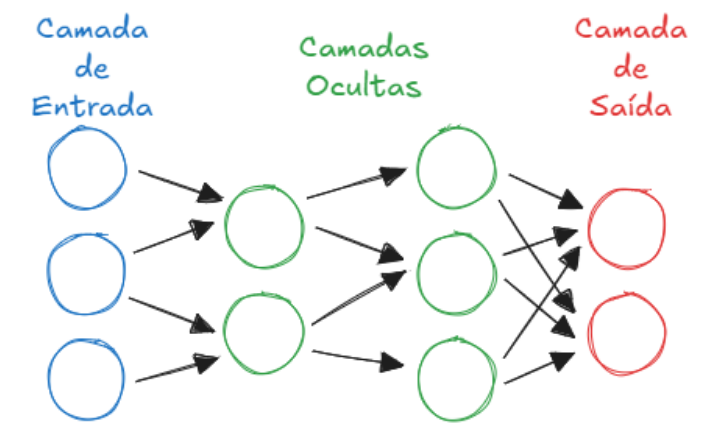
Para organizar uma rede neural, utilizamos camadas de neurônios artificiais interligados.
A camada de entrada apenas recebe os dados (vetor de características) e os repassa.
As camadas ocultas/escondidas realizam o processamento: cada neurônio soma os valores recebidos com pesos e viés, aplica uma função de ativação e envia o resultado (a ativação) adiante.
Por fim, a camada de saída gera o resultado final da rede, como um valor numérico (regressão) ou probabilidades para rótulos (classificação).
Deep Learning
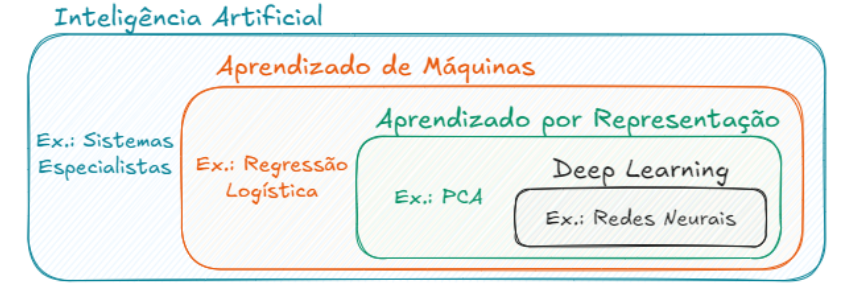
Algoritmos clássicos de IA, como a regressão logística, dependem de dados estruturados e da intervenção humana para definir quais atributos são relevantes. Eles não conseguem lidar diretamente com dados brutos, como imagens ou sons.
O Deep Learning resolve isso ao usar redes neurais profundas que aprendem automaticamente representações hierárquicas dos dados, das formas simples até conceitos complexos, permitindo trabalhar com dados não estruturados sem necessidade de pré-processamento manual.
Decorar essa imagem!!
Perceptron
O perceptron é o modelo mais simples de rede neural, usado para tarefas de classificação linear. Ele soma entradas ponderadas, aplica um limiar e gera uma saída binária. Uma pequena alteração nos pesos de um único perceptron na rede pode ocasionar grandes mudanças na saída desse perceptron.
As funções de ativação ajudam a controlar o comportamento do perceptron e, portanto, o impacto das mudanças nos pesos. Saibam que, cada função de ativação possui suas próprias características, nos permitindo manipular o funcionamento da rede.
O perceptron é o neurônio artificial raiz: recebe entradas, faz uma soma com pesos, aplica um limiar e solta uma saída binária. Foi o pontapé inicial das redes neurais!
Função de ativação
A função de ativação é usada em cada neurônio para transformar a soma ponderada das entradas em uma saída. Ela introduz não linearidade ao modelo, permitindo que a rede aprenda padrões complexos. Exemplos comuns são ReLU, sigmoid e tanh.
A função de ativação é tipo o filtro esperto do neurônio: transforma o sinal bruto em algo útil e ainda dá um toque de não linearidade pro modelo pensar fora da caixinha. ReLU, sigmoid e tanh são os clássicos!
Backpropagation
Backpropagation é o algoritmo utilizado para ajustar os pesos de uma rede neural durante o treinamento. Ele funciona propagando o erro da saída para trás, camada por camada, calculando os gradientes parciais da função de custo em relação aos pesos. Esses gradientes são usados para atualizar os pesos, geralmente com o auxílio de um otimizador como o Gradiente Descendente.
Diferente do SGD tradicional, que pode usar todo o conjunto de dados para calcular o gradiente, o backpropagation normalmente é aplicado em mini-batches, permitindo atualizações mais rápidas e eficientes. Essa abordagem é essencial para treinar redes profundas e lidar com grandes volumes de dados.
CEBRASPE (CESPE)/Ana TI (DATAPREV)/DATAPREV/Inteligência da Informação - 2023
As redes neurais têm a capacidade de adaptar seus pesos sinápticos considerando as mudanças de padrão dos dados de entrada.
Gabarito: Certo.
O backpropagation é o cérebro por trás do treino das redes neurais: ele calcula os erros na saída e os espalha para trás, ajustando os pesos passo a passo pra melhorar a precisão. É tipo o GPS que mostra onde o modelo errou e como corrigir.
MLP
Uma rede neural Perceptron Multicamadas (MLP) é um tipo moderno de rede feedforward cuja principal característica é possuir os neurônios totalmente conectados (isto é, todos neurônios da camada anterior estabelecem conexão com todos neurônios da camada seguinte).
Uma MLP tradicional trata todos os pixels igualmente, sem considerar sua posição na imagem, ignorando a localidade espacial — algo crucial para dados visuais. Para resolver isso, surgiram as Redes Neurais Convolucionais (CNNs), que processam pequenas regiões da imagem por vez, preservando padrões locais, como bordas e texturas, e permitindo um aprendizado visual mais eficiente.
As MLPs utilizam funções de ativação não lineares, como ReLU ou sigmoid, o que permite à rede aprender padrões complexos, inclusive não lineares.
CNN
As Redes Neurais Convolucionais (CNNs) são arquiteturas projetadas especialmente para processar dados com estrutura espacial, como imagens. Elas se distinguem por três tipos principais de camadas:
1 - Camadas convolucionais, que aplicam filtros para extrair padrões locais (bordas, texturas);
2 - Camadas de agrupamento (pooling), que reduzem a dimensionalidade e destacam os padrões mais relevantes;
3 - Camadas totalmente conectadas, usadas nas etapas finais para tomar decisões com base nas representações aprendidas.
Essa estrutura especializada garante desempenho superior em tarefas de visão computacional, sendo uma das principais vantagens das CNNs frente a outras redes tradicionais.
Elas extraem características intermediárias antes de prever a saída final.
Redes Neurais Convolucionais (CNNs) são especialistas em entender imagens e padrões visuais. Elas analisam pedaços pequenos dos dados (como regiões da imagem), detectando bordas, formas e estruturas, camada por camada.
São usadas em reconhecimento facial, diagnóstico por imagem (raios-X, ressonância), carros autônomos (detecção de obstáculos), filtros de redes sociais, leitura de placas (OCR) e até em sistemas de vigilância inteligente.