Modelagem Dimensional
Conceito
Modelagem Dimensional é uma técnica de design de banco de dados utilizada principalmente em sistemas de Business Intelligence (BI) e Data Warehousing, com o objetivo de otimizar a análise de dados e facilitar a tomada de decisões.
Ela foi popularizada por Ralph Kimball, um dos principais nomes da área.
O foco da modelagem dimensional é tornar os dados:
- Fáceis de entender por usuários finais
- Rápidos de consultar, mesmo com grandes volumes de dados
- Organizados de forma intuitiva, para responder a perguntas de negócio
A modelagem dimensional é baseada em dois tipos principais de tabelas:
-
Fato (Fact Table)
- Armazena os dados quantitativos do negócio (valores numéricos que podem ser medidos).
- Ex: vendas, lucros, quantidades, tempos.
-
Dimensão (Dimension Table)
- Armazena os atributos descritivos (contexto) usados para analisar os fatos.
- Ex: tempo, produto, cliente, localização.
Principais Modelos
-
Estrela (Star Schema):
A tabela fato no centro e as tabelas dimensão ao redor, ligadas diretamente a ela. -
Floco de Neve (Snowflake Schema):
Semelhante à estrela, mas com dimensões normalizadas (divididas em várias tabelas).
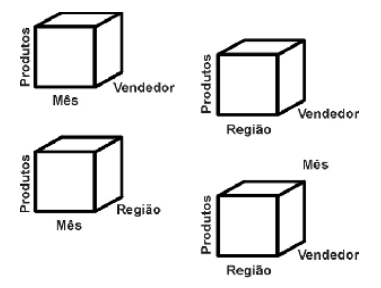
Cubo de dados
O Cubo de Dados (ou Cubo OLAP) é uma estrutura multidimensional usada em sistemas de Business Intelligence e Data Warehousing para facilitar a análise de grandes volumes de dados sob diferentes perspectivas (ou dimensões).
- Exemplo prático: Um cubo de vendas pode ter como dimensões:
- Tempo (dia, mês, ano)
- Produto
- Região
E como medidas (fatos): quantidade vendida, receita, lucro etc.
🔷 Como funciona?
Cada célula do cubo representa um valor agregado (como total de vendas) correspondente a uma combinação única das dimensões.
- É como uma tabela multidimensional, onde se pode detalhar (drill down), resumir (roll up), fatiar (slice) e dizer (dice) os dados.
Hipercubo
O termo hipercubo é usado quando o cubo tem mais de 3 dimensões (algo comum em sistemas reais). Por exemplo, um cubo com tempo, produto, região, canal de venda, e cliente já é um hipercubo com 5 dimensões.
- Um único cubo.
🌕 Hipercubo Denso
- Definição: Um hipercubo denso é aquele em que a maioria das combinações de dimensões possui dados registrados.
- Características:
- Poucos espaços vazios
- Mais memória e processamento necessários
- Consultas geralmente mais rápidas, pois há menos valores nulos ou ausentes
🌑 Hipercubo Esparso
- Definição: Um hipercubo esparso é aquele em que a maioria das combinações possíveis de dimensões não possui dados (ou seja, muitas células estão vazias).
- Características:
- Mais econômico em armazenamento se for bem implementado
- Consultas podem ser mais complexas, dependendo do SGBD ou ferramenta OLAP
- É o mais comum na prática, especialmente com muitas dimensões
🧠 Resumo:
| Conceito | Descrição |
|---|---|
| Cubo de Dados | Estrutura multidimensional para análise de dados |
| Hipercubo | Cubo com mais de 3 dimensões |
| Hipercubo Denso | Muitas combinações de dimensões com dados (poucos vazios) |
| Hipercubo Esparso | Muitas combinações sem dados (muitos vazios) |
Multicubo
Os multicubos segregam as dimensões diferentes em cubos diferentes. Ela é uma abordagem utilizada para melhorar o desempenho e a eficiência das consultas analíticas em ambientes de business intelligence. Em vez de depender de um único cubo para armazenar e processar todos os dados analíticos, a estrutura de multicubos envolve a criação de vários cubos especializados que são otimizados para diferentes tipos de consulta.
| Característica | Hipercubos Densos | Hipercubos Esparsos | Multicubos |
|---|---|---|---|
| Tamanho de Armazenamento | Tende a ser maior devido à densidade de dados | Tende a ser menor devido à presença de células vazias | Depende da quantidade e tamanho dos cubos |
| Desempenho | Geralmente oferece desempenho mais rápido devido à densidade de dados | Pode apresentar desafios de desempenho devido à análise de células vazias | Desempenho variável, dependendo da consulta |
| Granularidade | Pode oferecer detalhes mais refinados devido à densidade de dados | Pode ser limitada pela presença de células vazias | Pode variar dependendo da granularidade dos cubos individuais |
| Eficiência de Consulta | Consultas tendem a ser mais rápidas e eficientes | Consultas podem ser mais lentas devido à necessidade de processar células vazias | Depende da otimização dos cubos individuais |
| Manutenção e Gerenciamento | Pode ser mais simples de gerenciar devido à estrutura compacta | Pode exigir mais esforço de gerenciamento devido à presença de células vazias | Pode ser complexo devido à presença de múltiplos cubos especializados |
| Flexibilidade | Oferece flexibilidade em relação à análise detalhada | Pode limitar a flexibilidade devido à presença de células vazias | Pode fornecer flexibilidade ao oferecer diferentes perspectivas de análise |
| Adequação a Cenários | Bem adequado para cenários onde há uma alta densidade de dados | Mais adequado para cenários com espaço multidimensional | Pode ser adequado para cenários com requisitos analíticos diversos |
Tabela Fato
O que é?
É a tabela central da modelagem dimensional. Armazena dados numéricos e medidas de negócio.
📊 Contém:
- Métricas: valores que queremos analisar (ex: vendas, lucro, quantidade).
- Chaves estrangeiras: apontam para tabelas dimensão (ex: tempo, produto, cliente).
🔄 Exemplo de Métricas:
- Quantidade Vendida
- Receita
- Custo
- Tempo de Execução
🌐 Ligação com Dimensões:
Cada registro se relaciona com uma ou mais dimensões que dão contexto ao fato.
🧠 Importante lembrar:
A tabela fato depende das dimensões para ter significado.
As dimensões podem existir sem uma fato, mas a fato não faz sentido sozinha.
Granularidade dos dados
Granularidade é o nível de detalhe com que os dados são armazenados e analisados em um sistema de Data Warehouse ou Business Intelligence.
Quanto maior o grão, menor o detalhe.
Quanto menor o grão, maior o detalhe.
Tipos de Métricas
1 - Fato aditivo
São medidas que podem ser somadas em qualquer dimensão (tempo, produto, região etc.) sem perder o sentido.
Exemplos:
- Quantidade vendida
- Receita total
Vantagem:
Permite agregações flexíveis (por mês, ano, produto...) úteis para análises de negócio.
Importante:
Soma válida em todos os contextos de análise.
2 - Fato Não Aditivo
São fatos numéricos que não podem ser somados em todas as dimensões, pois a soma pode gerar distorções ou resultados sem sentido.
Exemplo:
- Número de pedidos
(Somar por produto e por dia pode causar duplicações)
Importante:
Não é por não ser numérico, mas porque as dimensões tornam a soma inválida.
📊 Uso correto:
Esses fatos devem ser analisados com cuidados específicos, como contagens distintas ou médias.
3 - Fato semi-aditivo
É um tipo de dado que pode ser somado em algumas dimensões, mas não em todas.
Exemplo:
- Estoque: pode ser somado por loja, mas não ao longo do tempo (soma diária não faz sentido).
Importante:
É parcialmente aditivo — exige cuidado na escolha das dimensões de análise.
📊 Resumo:
- ✅ Soma válida: em algumas dimensões
- ❌ Soma inválida: em outras
Tipos de Tabelas Fato
Fato Transacional
Uma tabela fato transacional é uma tabela que registra eventos individuais ou transações em um sistema. Ela armazena os detalhes específicos de cada ocorrência ou transação que ocorre em um determinado contexto. Essas tabelas são usadas para registrar informações detalhadas e granulares sobre eventos específicos, geralmente em um nível de transação ou operação.
Fato Snapshot Periódico
Uma tabela fato snapshot periódico é uma forma de tabela fato que captura e armazena um momento específico e periódico do estado de um conjunto de dados em um determinado momento.
Fato Snapshot Acumulado
Uma tabela fato snapshot acumulado, ou accumulated snapshot fact, é uma forma de tabela fato que armazena informações acumuladas ao longo do tempo. Em vez de registrar eventos individuais ou instantâneos periódicos como nas tabelas fato transacionais ou snapshot periódico, a tabela fato acumulado contém valores acumulados de medidas desde o início do período considerado até o momento atual.
Fato Sem Fato
É uma tabela fato que não possui medidas numéricas, apenas chaves estrangeiras que se conectam às dimensões.
Ela registra eventos ou ocorrências que aconteceram (ou não aconteceram), sem precisar armazenar valores.
- Para rastrear eventos: ex. presença do aluno em aula (sem necessidade de contar horas ou valores).
- Para responder perguntas do tipo: “Quem participou?”, “Quando aconteceu?”, “Quantos eventos ocorreram?”.
Tabela Dimensão
As tabelas dimensão são as tabelas periféricas, responsáveis por armazenar informações que dão subsídios aos fatos. Essas informações, chamadas de dimensões, envolvem dados descritivos, contextuais e qualitativos das transações.
Slowly-Changin Dimension
A Slowly Changing Dimension (SCD), ou Dimensão de Mudança Lenta, é uma tabela dimensão que faz literalmente o que seu nome aponta – muda lentamente, por períodos de tempo. Ela atualiza atributos como nome, endereço, que mudam, mas com uma frequência relativamente baixa.
Exemplo: Domicílio tributário
Podemos mudar esses dados de três formas:
Tipo 1) Sobrescrição: os dados são sobescritos, isso é, são substituídos pelos dados novos. É a abordagem menos recomendada.
Tipo 2) Adição de nova linha: com a mudança dos dados, adicionamos mais uma linha ao conteúdo.
É a abordagem mais recomendada.
Tipo 3) Adição de nova coluna: com a mudança dos dados, adicionamos mais uma coluna à tabela.
Conformed Dimension
É uma dimensão compartilhada entre duas ou mais tabelas fato, com o mesmo significado e estrutura em todo o data warehouse.
Uma dimensão conformada mantém a mesma consistência (mesmos atributos, chaves e conteúdo) independentemente do fato com o qual se relaciona.
Degenerate Dimension
É um atributo de dimensão armazenado diretamente na tabela fato, porque:
- Não tem informações suficientes para justificar uma tabela dimensão separada.
- Geralmente é um identificador único, como número de pedido, número da fatura, etc.
Vantagens:
- Simplifica o modelo dimensional
- Evita criar dimensões desnecessárias
- Melhora performance e facilita consultas
💡 Exemplo:
| pedido_id | produto_key | cliente_key | data_key | valor_total |
|---|---|---|---|---|
| 12345 | 88 | 14 | 20240105 | 250.00 |
Aqui,
pedido_idé uma dimensão degenerada, armazenada direto na tabela fato.
Role Playing Dimension
É uma mesma dimensão reutilizada várias vezes em uma única tabela fato, assumindo papéis diferentes.
Exemplo comum:
A dimensão DIM_TEMPO pode ser usada como:
data_vendadata_entregadata_emissao
Tudo na mesma tabela fato (FATO_VENDAS), mas com funções diferentes.
Por que usar?
- Evita duplicar estrutura de dimensão.
- Permite análises sob diferentes perspectivas temporais (ou outras).
Resumindo:
É a mesma dimensão sendo usada com nomes diferentes na tabela fato, de acordo com o papel que ela desempenha.
Star Schema
São esquemas de bancos de dados multidimensionais onde temos somente uma tabela fato central e as dimensões não são normalizadas. Temos apenas uma conexão direta entre as tabelas dimensão e a tabela fato.
- cada tabela fato estará ligada a 1 ou n tabelas dimensão (1:n)
- cada tabela dimensão estará ligada somente a uma tabela fato (1:1)
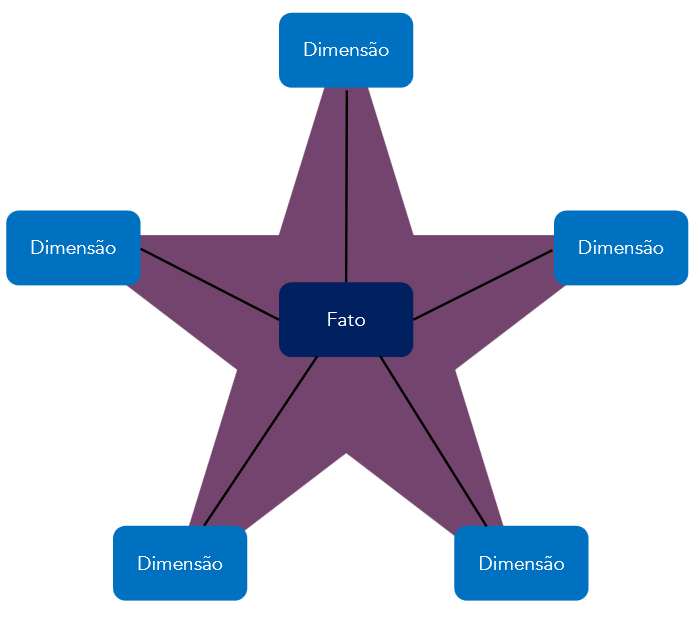
- Otimizado para suportar consultas de agregação de dados.
O modelo dimensional é desnormalizado para facilitar consultas rápidas e análises em sistemas de BI. Ele reduz o número de joins, melhora a performance e torna o modelo mais simples para usuários finais. É ideal para leitura, não para escrita frequente.
Snow Flake
Ele é chamado de "floco de neve" porque as tabelas dimensão são normalizadas, o que significa que elas são divididas em tabelas menores para remover a redundância de dados. Isso pode levar a uma estrutura de dados que se parece com um floco de neve, com tabelas interconectadas que se ramificam em várias direções.
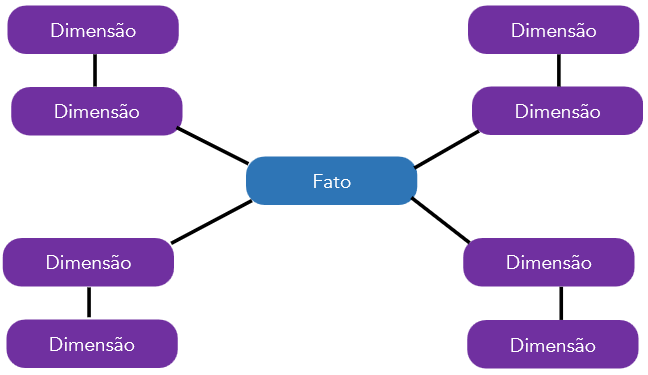
Tabela comparativa
| Característica | ⭐ Star Schema | ❄️ Snowflake Schema |
|---|---|---|
| Estrutura | Tabelas fato com dimensões diretas | Tabelas fato com dimensões normalizadas |
| Normalização | Desnormalizado | Normalizado |
| Desempenho de consulta | Mais rápido (menos joins) | Mais lento (mais joins) |
| Facilidade de uso | Mais simples para o usuário final | Mais complexo |
| Armazenamento | Requer mais espaço | Mais eficiente em espaço |
| Manutenção | Mais simples | Pode ser mais difícil |
| Uso comum | BI, dashboards, análises rápidas | Situações com alta redundância de dados |
Fact Constellation
A constelação de fatos é um esquema composto por múltiplas tabelas fato, interconectadas por intermédio de tabelas dimensão¸ que pode, ou não, ser normalizadas. Essas tabelas dimensão de ligação são justamente as tabelas de dimensão conforme.
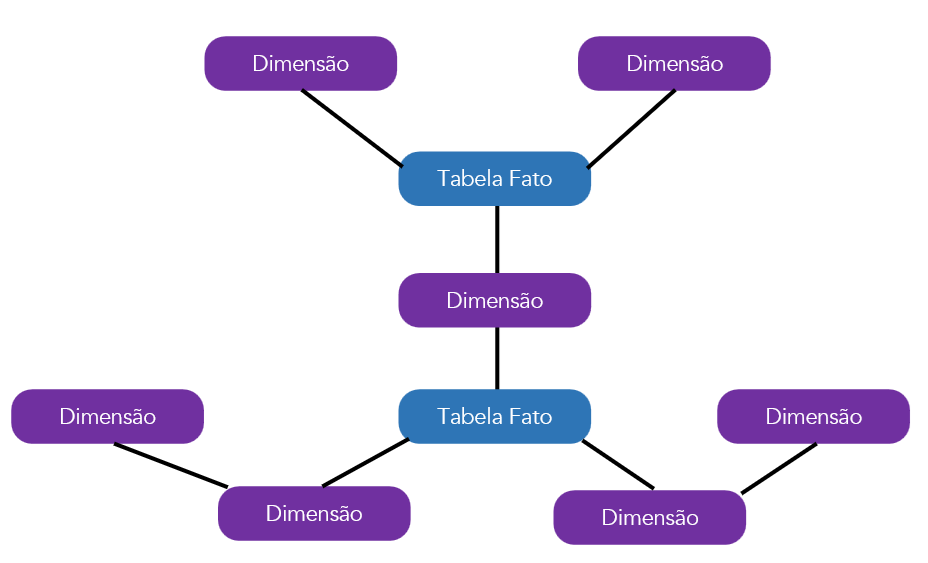
-
Modelo mais realista de funcionamento de um Data Warehouse, já que, numa entidade, podemos ter diversos fatos que queremos analisar.
- Há um compartilhamento de dimensões entre si e não de fatos
OLAP
OLAP (Online Analytical Processing) é uma técnica de análise de dados em diferentes perspectiva que se concentra na consulta interativa e na análise de grandes volumes de dados multidimensionais de maneira eficiente e rápida. Essa técnica emprega diferentes operações para navegarmos através as diferentes granularidades do cubo de dados.
Existem três tipos de arquiteturas:
• MOLAP (Multidimensional OLAP): é uma abordagem que armazena os dados em um cubo multidimensional e usa essa estrutura para consulta e análise. Os dados são pré-agrupados e armazenados em um formato de cubo, que pode ser facilmente navegado e analisado em diferentes dimensões. O MOLAP é ideal para análises rápidas de dados e é eficiente no uso de recursos do servidor, mas pode ser limitado em termos de escalabilidade e flexibilidade em relação a outras arquiteturas OLAP.
• ROLAP (Relational OLAP): é uma abordagem que usa um banco de dados relacional como fonte de dados para consulta e análise. Os dados são armazenados em tabelas relacionais e os usuários acessam esses dados por meio de uma camada de software OLAP. O ROLAP é altamente escalável e flexível em relação a outras arquiteturas OLAP, mas pode ser mais lento em termos de desempenho de consulta.
• HOLAP (Hybrid OLAP): é uma abordagem que combina características do MOLAP e do ROLAP. O HOLAP armazena dados detalhados em um banco de dados relacional e armazena dados agregados em um cubo multidimensional. Isso permite que os usuários analisem dados em diferentes níveis de detalhe e agregação, dependendo das necessidades da análise. O HOLAP oferece um bom equilíbrio entre desempenho e flexibilidade em relação a outras arquiteturas OLAP.
• OLTP (Online Transaction Processing) é o modelo tradicional de processamento de transações online, voltado para aplicações operacionais do dia a dia — como sistemas de vendas, bancos, cadastros e ERPs.
🧩 Resumo Comparativo – OLAP x MOLAP x ROLAP x OLTP
| Característica | OLTP | OLAP (geral) | MOLAP | ROLAP |
|---|---|---|---|---|
| Objetivo | Processamento transacional | Análise de dados | Análise com cubos multidimensionais | Análise usando banco relacional |
| Tipo de uso | Operacional | Gerencial / Decisório | Gerencial / Decisório | Gerencial / Decisório |
| Fonte de dados | Sistemas de produção | OLTP ou Data Warehouse | Cubos multidimensionais | Bancos relacionais (SQL) |
| Armazenamento | Relacional (MySQL, PostgreSQL) | Relacional ou multidimensional | Estrutura multidimensional própria | Bancos relacionais comuns |
| Performance (consultas) | Alta p/ transações pequenas | Alta p/ leitura e agregação | Muito alta (pré-processado) | Média (consultas SQL complexas) |
| Atualização dos dados | Frequente e em tempo real | Menos frequente (dados históricos) | Mais lenta (pré-processamento) | Mais rápida (dados vivos) |
| Exemplo de uso | Cadastro de clientes, vendas | Relatórios de desempenho | Dashboards com dados agregados | Relatórios dinâmicos e personalizados |
| Modelagem comum | Entidade-relacionamento (ER) | Estrela ou Floco de neve | Estrela (convertida em cubos) | Estrela ou Floco em banco relacional |
| Volume de dados | Pequeno a médio (por operação) | Grande (dados históricos agregados) | Médio (limitado à estrutura dos cubos) | Grande (escalável com banco relacional) |
Operações OLAP
As operações OLAP são um conjunto de operações que permitem que os usuários analisem e explorem dados multidimensionais em diferentes níveis de agregação. Com isso, temos diferentes visões dos dados, de forma a favorecer a análise.
- Slice: Corte simples de uma dimensão (ex: "Ano 2024").
- Dice: Corte multidimensional (ex: "Ano 2024", "Região Norte", "Produto A").
- Drill Down: Aprofunda os dados para um nível mais detalhado. Maior Granularidade.
- Drill Through: Acessa dados detalhados diretamente na base de dados.
- Roll Up: Agrega dados para um nível superior. Menor Granularidade!
- Pivot: Reorganiza a perspectiva dos dados, alterando dimensões.
Tabela Comparativa
| Operação | Objetivo | Como Funciona | Exemplo |
|---|---|---|---|
| Slice | Realiza um corte de uma dimensão, selecionando um único valor. | Seleciona um valor específico de uma dimensão, resultando em uma visão 2D dos dados. | Cortar o cubo por Ano 2024, para mostrar as vendas por Produto e Região nesse ano. |
| Dice | Realiza um corte multidimensional, selecionando valores de várias dimensões ao mesmo tempo. | Filtra dados com base em intervalos ou conjuntos de valores de duas ou mais dimensões. | Cortar o cubo pelos valores de Ano 2024, Região Norte e Produto A, mostrando vendas. |
| Drill Down | Aprofunda os dados, indo para um nível mais detalhado dentro de uma dimensão. + Granularidade | Expande uma dimensão para mostrar informações mais específicas ou granular. | "Drill down" no Ano 2024 para ver as vendas por mês ou dia (em vez de por ano). |
| Drill Through | Acessa os dados originais subjacentes (banco de dados relacional), permitindo detalhes. | Vai para a base de dados relacional para obter os dados completos e não agregados. | "Drill through" nas vendas de Janeiro 2024 para ver as transações individuais no banco. |
| Roll Up | Agrega dados para um nível superior, resumindo informações. | Consolida os dados de um nível mais detalhado para um nível mais agregado. | "Roll up" de vendas diárias para vendas mensais ou anuais. |
| Pivot | Reorganiza os dados, alterando a perspectiva das dimensões. | Troca as dimensões de posição para criar diferentes visões ou comparações dos dados. | Trocar as dimensões de Produto e Região para visualizar as vendas por região e produto. |