IA - Conceitos e Ética
PLN - Linguagem Natural
O Processamento de Linguagem Natural, ou PLN, combina poder computacional, inteligência artificial e linguística humana para permitir dispositivos computacionais a reconhecerem, entenderem e gerar texto e fala. Em linguagem aqui, temos uma interpretação - então, temos a linguagem escrita, falada e símbolos sendo interpretados.
Algumas aplicações do PLN envolvem:
• Tradução de textos (escritos e falados)
• Resposta a falas
• Reconhecimento de voz
• Sumarização de conjuntos de texto
• Identificação de sentimento
• Geração de texto ou gráficos
O processo de desenvolvimento de um PLN envolve, usualmente, as seguintes etapas - que não necessariamente seguirão uma linha temporal contínua:
• Pré-Processamento do Texto: Os dados são conjuntos de textos. Graças a isso, temos algumas práticas específicas dessa área:
o Tokenização: dividir o texto em unidades menores, como frases, palavras ou subpalavras - esse bloco é chamado de token.
o Remoção de stop words: stop words são palavras irrelevantes para o sentido do texto, como artigos e preposições. Elas são removidas para diminuir a dimensionalidade, a quantidade de variáveis no texto.
• Tagging ou etiquetagem: envolve atribuir rótulos às palavras. Esses rótulos podem, dentre outros, ser atribuídos conforme a classe gramatical, com o Part-of-Speech Tagging (POS Tagging), ou com base em entidades nomeadas (entidades reconhecidas, como empresas), com o NER (Named Entity Recognition).
O POS-Tagging é uma forma de etiquetagem de palavras, que atribui um rótulo a uma palavra baseado na sua classe gramatical.
• Análises semânticas e sintáticas: podemos analisar o texto, quase como uma etiquetagem, conforme o significado semântico ou sintático da palavra no contexto analisado.
• Vetorização: é a conversão de dados textuais em vetores, isso é, números que ocupam algum espaço num plano bidimensional ou tridimensional, como um ponto no espaço, permitindo que algoritmos computacionais lidem com essa. Temos diversas técnicas, como Word Embeddings, TL-IDF, entre outros.
Embeddings
Embeddings são representações vetoriais (numéricas) de palavras, frases ou documentos.
Em vez do computador enxergar palavras como texto cru (ex: "cachorro", "gato"), ele transforma cada uma em um vetor com várias dimensões (tipo [0.25, -0.78, 0.42, ...]) que captura o significado dessas palavras. Isso permite que o modelo “entenda” similaridade semântica entre elas.
Ex: “Técnicas populares incluem Word2Vec, GloVe, FastText e BERT (para embeddings contextuais).”
Banco Vetorial
Um banco vetorial (ou vector database) é um tipo especial de banco de dados que guarda embeddings (ou seja, vetores numéricos que representam textos, palavras, frases, imagens etc.).
Ele permite fazer buscas por similaridade, em vez de buscar por palavras exatas.
Imagine que você tem 10 mil documentos transformados em vetores. Aí chega uma pergunta nova do usuário, que também é transformada em vetor. O banco vetorial serve pra comparar rapidamente esse vetor novo com todos os armazenados e encontrar os mais parecidos (ou seja, os mais relevantes).
Utiliza: Similaridade do cosseno, Distância Euclidiana, Distância de Manhattan.
Busca Semântica
Busca semântica é um tipo de busca que não se baseia só em palavras exatas, mas sim no significado das palavras. Ela compara conceitos em vez de só fazer uma correspondência literal de termos.
Na prática, a consulta do usuário também é transformada em embedding e comparada com os vetores armazenados no banco vetorial, usando métricas como a similaridade do cosseno. Assim, o sistema recupera os conteúdos semanticamente mais relevantes.
IA Generativa
Conceito
As Inteligências Artificiais Generativas são inteligências voltadas à criação de uma variedade de dados - imagens, vídeos, áudios, textos, modelos 3D, e por aí vai. As IAs generativas são dotadas de uma extrema capacidade computacional, produzindo conteúdos complexos e altamente realistas.
- São fundamentalmente baseados em aprendizado não supervisionado.
Geração de Texto
Para gerações de texto, é usual que sejam usados diferentes tipos de redes neurais, como a Rede Neural Recorrente e a Rede Transformer, ou a Cadeia de Markov (ou Markov chain).
A cadeia de Markov, com modelo estocástico, ajuda a IA a prever a próxima palavra ou ação com base na anterior, tornando possível criar frases com sentido e auxiliar na escrita automática.
Geração de Imagens, Vozes e Vídeos
Para gerações de imagens, costuma-se usar algoritmos de aprendizado profundo, uma espécie de rede neural especializada, mais complexa.
Exemplos de tipos de redes neurais de aprendizado profundo utilizadas são as Redes Generativas Adversárias (GAN) e as redes de Autoencoder Variacional. Em uma rede adversária generativa (GAN), o gerador cria dados e o discriminador avalia se esses dados pertencem ao conjunto de treinamento real.
Redes Generativas Adversariais (GANs)
Duas redes neurais que competem entre si:
1 - Gerador (Generator): cria dados falsos (ex: imagens, textos)
2 - Discriminador (Discriminator): tenta distinguir se os dados são reais ou gerados
Funcionamento:
- Gerador tenta enganar o Discriminador
- Discriminador tenta identificar o falso
- Esse "jogo" melhora ambos com o tempo
Objetivo:
Gerar dados realistas que imitam dados verdadeiros
(ex: rostos humanos, vozes, textos, obras de arte)
Aplicações:
- Deepfakes
- Criação de imagens realistas
- Geração de música e arte
- Aumento de dados para treino de IA
Large Language Models
Um LLM é uma IA generativa especializada em reconhecer e gerar textos.
Sua principal característica é o uso de grandes volumes de dados no treinamento.
Esses modelos utilizam redes neurais do tipo transformer e se baseiam em aprendizado profundo (deep learning), permitindo que o próprio modelo compreenda e processe os dados de forma autônoma e sofisticada, com pouco pré-processamento externo.
- Utiliza a rede neural transformers.
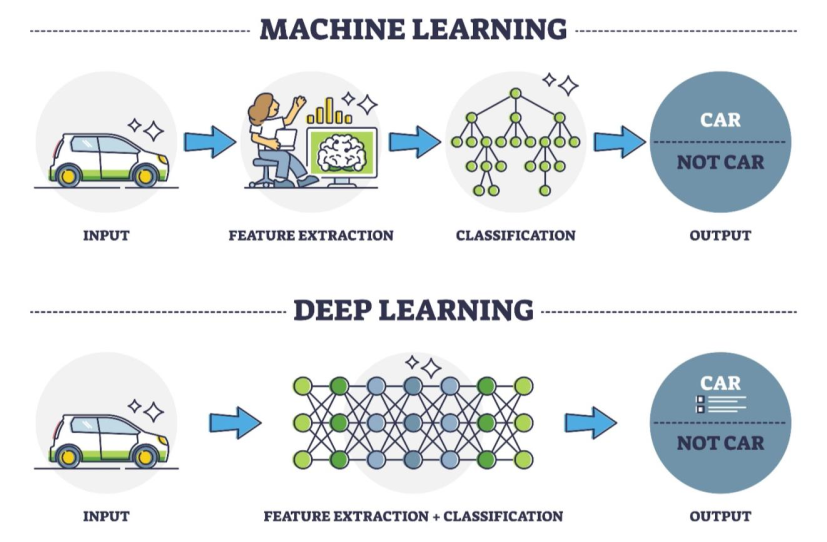
Exemplos envolvem ChatGPT, Bard, Copilot, e outros, além de chatbots mais interativos.
Mixture of Experts
É uma técnica de aprendizado de máquina que divide o problema em diversos especialistas. Especialistas são modelos individuais que são especializados em aprender padrões específicos ou características dos dados. Cada especialista é treinado para resolver um subproblema específico dentro do problema global. Os especialistas podem ser modelos de diferentes tipos (por ex., redes neurais, árvores de decisão) ou múltiplas instâncias do mesmo tipo de modelo, treinados em subconjuntos distintos dos dados.
Esses especialistas são conectados por uma rede chamada de Rede de Detecção, ou Gated Network. A rede é responsável por determinar o quanto cada especialista deve contribuir para a predição final.
A rede de seleção recebe as mesmas entradas dos especialistas e gera um conjunto de pesos (probabilidades) para cada especialista. Esses pesos determinam a influência de cada especialista na predição final. A rede de seleção é treinada junto com os especialistas para aprender a melhor maneira de combinar suas previsões.
Por que isso é útil?
- Economiza energia e tempo
- Deixa a IA mais rápida e inteligente
- Ajuda a lidar com tarefas complexas, dividindo o trabalho
Parâmetros de LLM
Assim como um cachorro precisa de comandos para fazer truques, uma LLM precisa de parâmetros para funcionar corretamente. Esses parâmetros definem seu comportamento e são ajustados principalmente via API, não nas interfaces comuns como o ChatGPT.
Além disso, a conversa com uma LLM pode ser armazenada em uma "thread", que guarda o histórico para evitar repetições e manter o diálogo mais fluido e coerente.
🧠 1. Número de Parâmetros
Quantidade de "pesos" treináveis. Quanto mais, maior a capacidade do modelo.
🧾 2. Tamanho do Contexto (Tokens)
Limite de palavras/fragmentos que o modelo analisa por vez. Afeta coerência.
📈 3. Taxa de Aprendizado (Learning Rate)
Controla o ritmo de aprendizado no treinamento. Muito alto = instável, muito baixo = lento.
🔥 4. Temperature
Controla a criatividade das respostas:
- Baixo como 0,1 = mais previsível
- Alto como 0,9 = mais variado/aleatório
💬 5. Prompt
É o texto de entrada que serve como uma instrução para a LLM.
É a pergunta que tu faz todo dia no ChatGpt.
Retrieval-Augmented Generation (RAG)
É uma técnica para aprimorar a acurácia e a confiabilidade dos modelos generativos, com fatos recuperados de fontes externas.
O RAG é uma técnica usada para superar a limitação dos LLMs, que não conseguem acessar ou aprender informações novas após o treinamento.
Problema que resolve:
LLMs são treinados com dados fixos. Com o tempo, esses dados se tornam desatualizados, e reentreinar o modelo com novos dados é difícil e caro.
Como o RAG funciona?
O processo acontece em duas etapas principais:
1️⃣ Recuperação de Informação (Retrieval)
O sistema busca documentos ou trechos relevantes de uma base externa (artigos, PDFs, manuais, bancos de dados, etc.) com base no prompt do usuário.
🔍 Técnicas comuns:
- Vector search (busca vetorial com embeddings)
- BM25 (baseado em palavras-chave e frequência)
- Outras técnicas semânticas ou textuais
Os embeddings vetoriais transformam o texto em representações numéricas que permitem ao sistema comparar a similaridade semântica entre consultas e documentos em um espaço de alta dimensão.
2️⃣ Geração de Texto (Generation)
O modelo de linguagem (como o GPT) recebe o prompt original + os textos recuperados, e com isso gera uma resposta mais precisa e atualizada.
✅ Resumo simplificado:
O RAG permite que a IA busque informações atualizadas em fontes externas antes de responder. Ele junta o melhor de dois mundos:
🧾 Recuperação de dados + ✍️ Geração natural de texto.