Business Inteligence
Conceito
A Inteligência de Negócios, Business Intelligence ou simplesmente BI, é um conjunto de técnicas, processos e ferramentas utilizadas para transformar dados brutos em informações significativas e úteis para a tomada de decisões estratégicas nas organizações.
Ferramentas de extração e transformação:
- ETL (Extract, Transform, Load).
- ELT (Extract, Load, Transform).
Ferramentas de Armazenamento:
- Data Warehouse.
- Data Lake.
- Data Mesh.
Ferramentas e Técnicas de Análise:
- Visualização de dados.
- OLAP.
- Análises de tendência.
- Machine Learning.
- Programas de análise (Power BI, QLik View).
Podemos considerar que o processo do Business Intelligence envolve uma abordagem iterativa, onde cada ciclo de ações é repetida indeterminadas vezes, até que seja alcançado o resultado desejado: obter informações relevantes para a entidade. Podemos definir esse ciclo nas seguintes ações:
• Coleta de Dados: O primeiro passo do BI é justamente coletar os diferentes dados para serem usados nas decisões. Esses dados podem ser estruturados, oriundos de bancos de dados relacionais, por exemplo, ou não estruturados, oriundos das mais diversas fontes geradoras de informação;
• Processamento e Transformação: Muitas vezes é necessário que os dados estejam em algum padrão, tendo certo nível de estruturação, antes de serem armazenados. Por esse motivo, passam por um processo de análise, descarte de dados inutilizáveis e transformação para o padrão do repositório de destino;
• Armazenamento de dados: Precisamos de repositórios que suportem alto volume de dados, para permitir que as ferramentas de análise tenham um desempenho mais elevado;
• Análise: Utilizam-se diferentes técnicas, como visualização de dados (gráficos, tendências), mineração de dados, técnicas OLAP, para obter informações relevantes que auxiliarão a tomada de decisões da entidade;
• Tomada de decisão: Com base nas informações encontradas, busca-se tomar as decisões ótimas para a evolução da entidade.
KDD
KDD (Knowledge Discovery in Databases) é o processo de descoberta de conhecimento em bases de dados. Ele envolve uma série de etapas para transformar dados brutos em informações úteis e padrões compreensíveis que apoiam a tomada de decisão.
🔁 As 5 Etapas do KDD
-
Seleção
Escolher os dados relevantes a partir de várias fontes (ex: planilhas, sistemas, bancos de dados). -
Pré-processamento
Limpar os dados: Remoção de dados duplicados, remoção de dados ruidosos, tratamento de valores ausentes, remoção de outliers, entre outros. -
Transformação
Organizar os dados em um formato adequado para análise, como normalização, agrupamento ou categorização. -
Mineração de Dados (Data Mining)
Aplicar técnicas estatísticas ou de aprendizado de máquina para encontrar padrões, correlações, análises preditivas, entre outros. -
Interpretação e Avaliação
Analisar e validar os padrões encontrados, traduzindo em conhecimento útil para ações práticas.
✅ Exemplo prático (Tribunal de Justiça):
O TJ-PA pode usar o KDD para descobrir, por exemplo, que há aumento de atendimentos em direito de família após feriados prolongados, o que ajuda no planejamento de pessoal e estrutura.
ETL
É um acrônimo para “Extract, Transform and Load” (Extrair, Transformar e Carregar)
Nesse tipo de pipeline, temos três etapas distintas que ocorrem antes do dado ser armazenado no destino:
• Extração (Extraction)
• Transformação (Transformation)
• Carregamento (Load)
Extração
A etapa de extração é a primeira fase do processo, na qual os dados são coletados a partir de diversas fontes, como bancos de dados, arquivos CSV, APIs, sistemas legados, entre outros — perceba, então, que a extração poderá lidar com dados estruturados e não estruturados.
Ela pode ser realizada de diferentes maneiras, dependendo da origem dos dados e das ferramentas utilizadas.
Transformação
Nessa etapa, os dados extraídos são modificados, limpos, enriquecidos e reestruturados de acordo com as necessidades do destino final. Pode envolver atividades como limpeza de dados, integração de dados, enriquecimento de dados, discretização.
Discretização - Transformar variáveis contínuas em variáveis discretas.
Exemplo: Jovem 0–24, Adulto 25–59, Idoso 60+.
Normalização
É o processo de ajustar os valores para uma escala comum, sem alterar a lógica dos dados. Isso melhora o desempenho e a precisão das análises e algoritmos.
- Geralmente entre 0 e 1, sem distorcer as diferenças entre eles.
- Alguns algoritmos (como KNN ou redes neurais) funcionam melhor e com mais precisão quando os dados numéricos estão em uma escala padronizada.
Padronização (Z-Score)
É usada quando os dados têm escalas diferentes e o modelo precisa trabalhar com variação estatística.
Serve para centralizar os dados (média = 0) e padronizar sua dispersão (desvio padrão = 1).
É ideal em algoritmos como regressão, PCA, SVM e modelos baseados em distância.
Outliers
Outliers são pontos de dados que se diferenciam significativamente do restante do conjunto de dados. Eles podem representar observações incomuns, extremas ou até mesmo erros de medição. A presença de outliers pode distorcer a análise estatística e prejudicar a precisão dos modelos, tornando sua detecção e remoção uma etapa importante no pré-processamento de dados.
Staging Area - Zona de pouso
A Staging Area não é uma técnica de tratamento de dados, e sim um “lugar” onde essas técnicas ocorrem. Ela serve como um espaço temporário onde os dados extraídos são armazenados e preparados antes de serem carregados no destino final, como um data warehouse.
Operational DataBase
Um Operational Database (ou banco de dados operacional) é um sistema usado para armazenar e gerenciar os dados das atividades rotineiras de uma organização em tempo real.
Ele serve de base para os sistemas operacionais que registram cadastros, atualizações, atendimentos, movimentações, etc.
Essas informações são armazenadas automaticamente em um banco MySQL, que funciona como o banco operacional do sistema.
Carregamento
O carregamento é a última etapa da nossa pipeline ETL. Ele é responsável por coletar o conjunto de dados transformados na Staging Area e carregá-los nos repositórios de dados em lotes ou em tempo real, como o Data Warehouse e o Data Lake. Esse é um processo lento, visto que a quantidade de dados inserida, muitas vezes, é massiva, por isso recebe relevante atenção.
ELT
Aqui temos um acrônimo para as três mesmas etapas - Extract (Extrair), Load (Carregar) e Transform (Transformar).
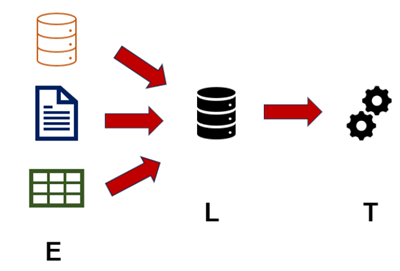
- Quando utilizar esse formato?
É usado quando o Data Warehouse é robusto o suficiente para transformar os dados internamente, após carregá-los.
Quando você faz a transformação dos dados em uma etapa prévia, isso acaba aumentando a latência na carga ou, em outras palavras, aumentando o tempo que se leva para pegar o dado lá do ponto de origem e inserir no repositório de destino. Muitas vezes, é necessário que tenhamos o dado gerado rapidamente, principalmente quando estamos usando ferramentas que usam quantidades massivas de dados, como uma inteligência artificial.
ETL vs ELT
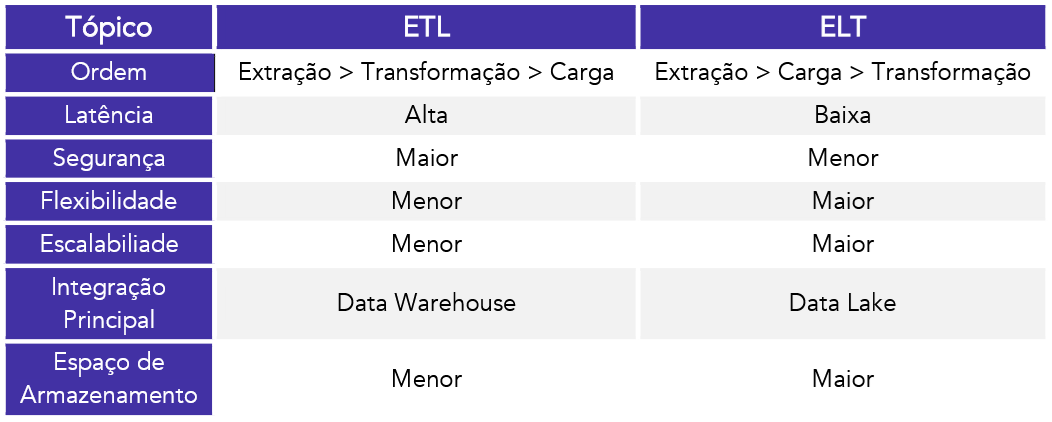
-
ETL (Extract, Transform, Load) é ideal para Data Warehouses, pois os dados são tratados antes da carga, garantindo segurança(LGPD), padronização e menor espaço ocupado. É bem mais cara que a ELT.
⚠️ Porém, isso gera maior latência (tempo) no carregamento.
-
ELT (Extract, Load, Transform) é usado com Data Lakes, onde os dados são carregados brutos e rapidamente, favorecendo velocidade e escalabilidade para análises como IA e machine learning.
⚠️ Em compensação, tem menos organização, maior risco de segurança e mais consumo de armazenamento.
Data Warehouse
Um Data Warehouse, ou Armazém de Dados, é um repositório centralizado de dados, que trabalha com dados estruturados, e destinado a suportar análises de dados com foco no Business Intelligence.
A arquitetura do Data Warehouse é dividida em três camadas:
- Camada superior: Interface com o usuário — onde se aplicam análises, relatórios e BI.
- Camada intermediária: Faz a ponte entre a interface e os dados, gerenciando o acesso e consultas.
- Camada inferior: É o servidor do banco de dados, onde os dados ficam armazenados.
Os Data Warehouses possuem quatro pilares essenciais, que orientam todo o seu funcionamento. São as características mais preponderantes de sua estrutura: orientação a assunto, não volatilidade, variância no tempo, integração.
-
Orientado a assunto - É projetado para lidar com informações específicas sobre um determinado assunto ou tópico de negócios, como vendas, finanças ou estoque.
-
Não volátil - É projetado para armazenar dados históricos de negócios, que não mudam após a inserção.
-
variante no tempo - É projetado para manter informações históricas e permitir a análise de dados em diferentes períodos de tempo.
-
Integrado - É projetado para integrar dados de diversas fontes, para fornecer uma visão única e consistente dos dados de negócios.
Data Marts
Os data marts são subconjuntos de um data warehouse focados em uma área específica do negócio. Eles podem ser implementados rapidamente para atender às necessidades de diferentes departamentos e oferecem um escopo mais restrito de dados, melhorando o desempenho das consultas e a relevância das informações.

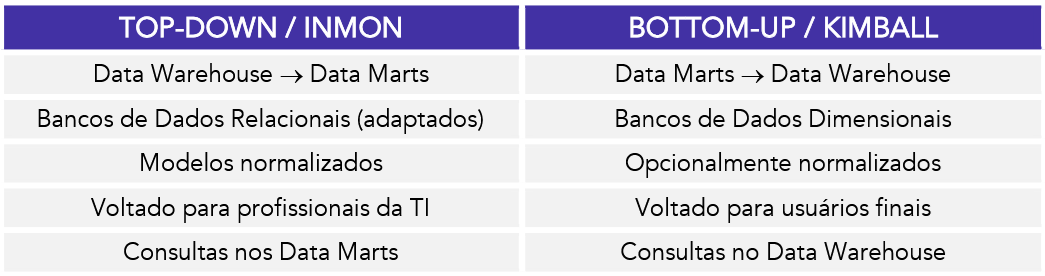
- Abordagem Inmon (Top-Down) prega que primeiro deve-se construir o todo, para depois as subdivisões, Dessa forma, primeiro construímos o Data Warehouse como um todo, que recebe o nome de EDW - Enterprise Data Warehouse, ou Armazém de Dados Corporativo. É empregada uma modelagem normalizada, onde os dados são armazenados em tabelas altamente normalizadas - usualmente na 3FN.
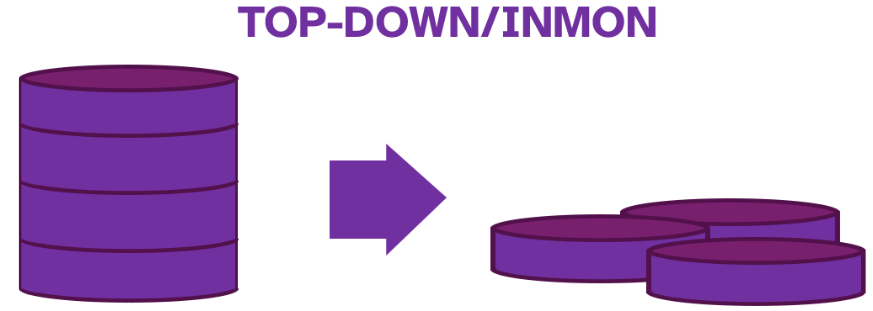
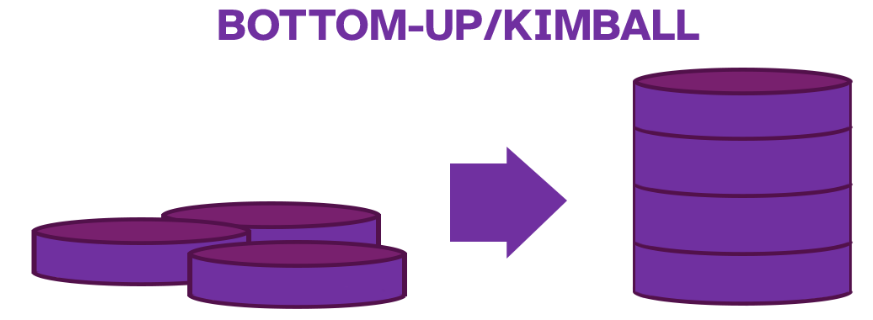
- Abordagem de Kimball (bottom-up), temos a criação primária sendo baseada nos Data Marts. Assim, conseguimos atender necessidades de setores específicos antes de criarmos o “todo”. Nesse sentido, Kimball introduz um conceito muito importante, que é o motivo pelo qual esse é o modelo mais abordado por questões: o banco de dados dimensional.
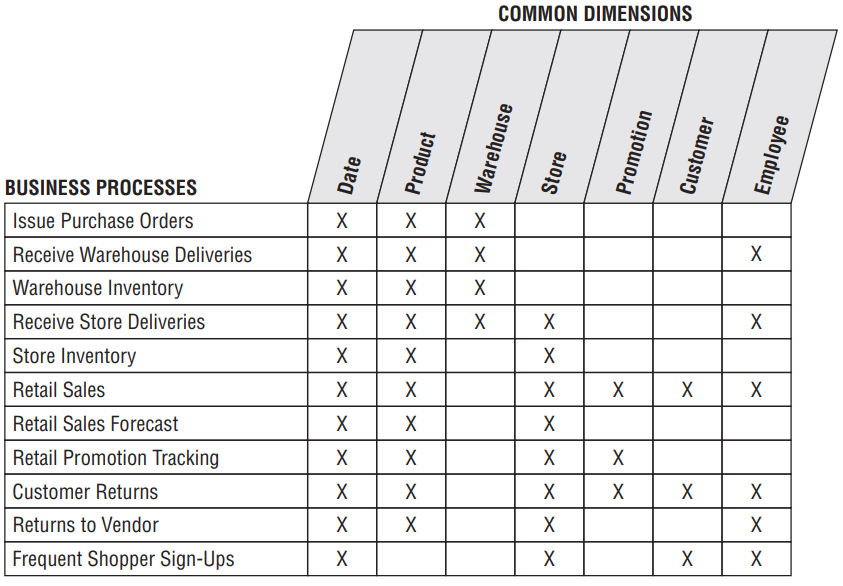
Matriz de barramento
A Matriz de Barramento é uma ferramenta de projeto usada para mapear os processos de negócios e identificar as dimensões que serão compartilhadas entre diferentes áreas de negócio. Ela facilita a criação de um Data Warehouse Corporativo ao permitir a implementação incremental de modelos dimensionais, assegurando que as dimensões padronizadas sejam reutilizadas e mantidas de maneira consistente. A matriz define um esqueleto que organiza como os dados de diferentes partes da organização serão integrados e utilizados.
Data Lake
Data Lake, ou lago de dados, são repositórios centralizados que permitem armazenar dados estruturados e não estruturados em qualquer escala. Ou seja, é possível o armazenamento dos dados sem a necessidade prévia de transformação e adaptação do dado ao padrão do repositório.
Características do Data Lake
-
Armazena dados brutos (sem tratamento)
→ Dados são carregados no formato original, sem transformação prévia. -
Alta escalabilidade
→ Suporta grandes volumes de dados (estruturados, semi-estruturados e não estruturados). -
Flexibilidade de formato
→ Aceita textos, imagens, vídeos, logs, JSON, CSV, entre outros. -
Velocidade no carregamento
→ Os dados são inseridos rapidamente (modelo ELT), ideal para tempo real ou quase real. -
Voltado para ciência de dados, IA e machine learning
→ Fornece uma base rica para análise avançada. -
Baixa estrutura e padronização
→ Pode ser desorganizado, exigindo mais esforço na transformação posterior. -
Maior risco de segurança e dados inúteis ("lixo")
→ Por aceitar tudo, é mais vulnerável a inconsistências e uso indevido se não houver controle.
Pode ser operacionalizado de duas formas:
1) Como intermediário, alimentando um Data Warehouse via ETL/ELT.
2) Como destino final, com governança e metadados, atuando como um Data Lakehouse, pronto para análise direta.
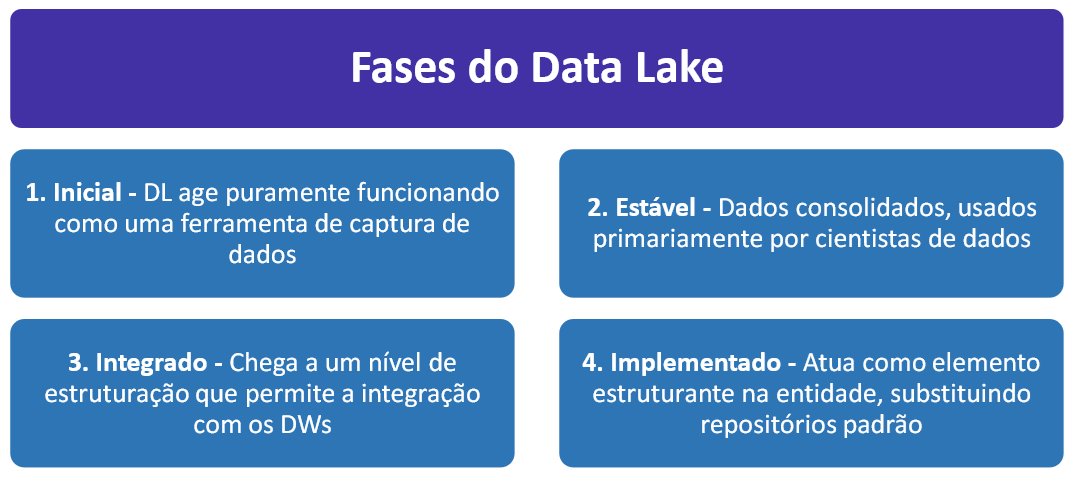
Etapas do desenvolvimento de um Data Lake
- Estágio 1 - Inicial - Captura de dados: Ele armazena os dados indefinidamente antes de qualquer processamento. Para evitar que vire um Data Swamp (pântano de dados), é essencial aplicar governança e classificação rigorosa logo no início.
- Estágio 2 - Estável - Ambiente de Ciência de Dados: Cientistas de Dados passam a usar o repositório como um sandbox, com acesso rápido a dados brutos para testar, prototipar e desenvolver análises.
- Estágio 3 - Integrado - Integração com Data Warehouses: o Data Lake é integrado ao Data Warehouse (EDW).
- Estágio 4 – Implementado - Componente estruturante: Neste estágio, o Data Lake se torna parte central da infraestrutura de dados da empresa. Ele substitui Data Marts e armazéns operacionais, distribui dados como serviço, e suporta análises avançadas e Machine Learning. Empresas podem até desenvolver aplicativos e painéis de desempenho diretamente sobre o Data Lake ou integrá-lo via APIs com outros sistemas.